
Every Ethereum node stores the blockchain — but not all of them remember the same amount of it. That’s the whole story behind full node vs archive node, and it’s the detail that decides how much disk you burn, how long you wait to sync, and which questions your node can actually answer. A full node keeps the chain running and remembers the recent past. An archive node remembers everything, all the way back to 2015. Pick the wrong one and you either can’t fetch the data you need, or you’re paying for terabytes you’ll never touch. This guide walks the difference from the ground up — what each node type is, why archive nodes exist, who actually needs one, and how to run or reach either without a month of syncing.
What is a blockchain node, and what are the node types?
Start with the basics. A blockchain node is just a computer running the client software that stores the ledger and checks every new block against the rules. On Ethereum, thousands of these nodes keep independent copies of the chain, which is what makes it so hard to cheat — there’s no single database to attack. When people talk about node types on a blockchain, they usually mean three: light nodes, full nodes, and archive nodes. They differ in one thing above all — how much of the chain’s history each one keeps on disk.
A light node travels light. It stores only block headers — enough to verify data on request — and leans on full nodes for the rest, which makes it a fit for phones and low-power devices. A full node carries the whole current picture. An archive node carries the whole history too. Most of this guide is about those last two, because that pairing is the choice that trips people up and costs real money when they get it wrong.
What is Full node?
A full node is the workhorse of the network. It validates every block, holds the complete current state, and hands over recent data on demand. But it doesn’t hoard the past. To stay lean, a full node keeps only the recent history — the state for roughly the last 128 blocks, about 25 minutes of chain at Ethereum’s 12-second block time. Everything older gets pruned, discarded on purpose to save space. Ask a full node for a balance from beyond that window and it can’t just look it up; the data isn’t there anymore.
Here’s what that costs you in 2026. A full node’s execution client runs about 0.9–1.3 TB, with another 80–200 GB for the consensus client and 100–150 GB for blob data (ethereum.org, Geth’s hardware guide). The whole chain pushed past 3 TB in mid-2025, so most people run a 4–8 TB NVMe drive and forget about it for a couple of years. The upside is speed: syncing a fresh full node takes hours to a few days, not weeks. For validating the chain, running a wallet backend, or powering a dapp that only touches recent state, a full node is all you need.
State, history, and why nodes prune
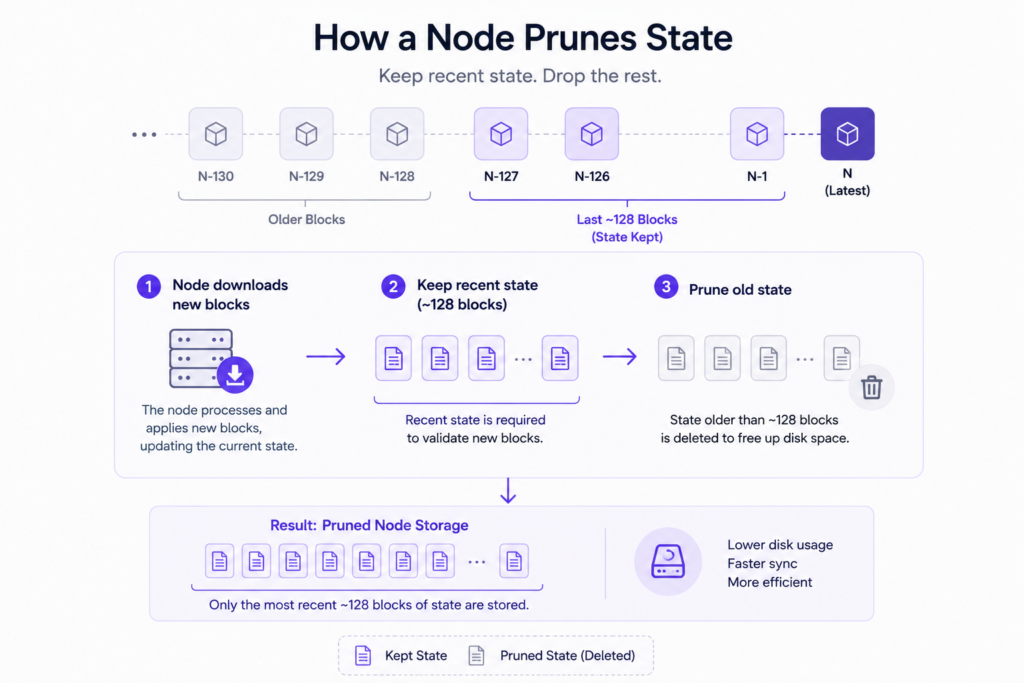
To see why the two node types split apart, you need one idea: state. State is the blockchain’s current snapshot — every account balance and every contract’s stored data, as of the latest block. The chain rewrites that snapshot with each new block, and checking fresh blocks only ever needs the recent version. Old state is dead weight for everyday operation; nothing about keeping the network alive depends on what an account held two years ago. So most clients prune it — they hold the state for the last 128 blocks or so, then drop the rest to reclaim disk. That one decision, prune or keep, is the fork in the road for every node that follows.
What is Archive node
An archive node starts where the full node stops. It keeps everything a full node does, then holds onto every historical state the chain has ever had — a full snapshot at every block since the genesis block in 2015. That’s what lets it answer questions about the deep past instantly. What did this wallet hold at block 15,537,393? What did that contract’s storage look like three years ago? A pruned node would have to replay millions of transactions to reconstruct the answer. This one just reads it off the disk.
All that history has a price, and it’s steep. Legacy Geth archives still top 12 TB. Erigon does the same job in under 3 TB, Reth lands near 2.8 TB, and newer path-based storage pulls Geth back toward ~2 TB (ethereum.org archive nodes). Building one from scratch means re-executing every transaction since 2015 — a sync that can run up to a month on consumer hardware. And the disk only grows from there. Whichever client you choose, an archive node is a long-term commitment, not a weekend project.
This isn’t a problem only hobbyists feel. Ethereum’s own builders run straight into it. Writing in May 2024, co-founder Vitalik Buterin described the archive-capable node on his own laptop:
“On the laptop that I am using to write this post, I have a reth node, and it takes up 2.1 terabytes — already the result of heroic software engineering and optimization. I needed to go and buy an extra 4 TB hard drive to put into my laptop in order to store this node. We all want running a node to be easier.” — Vitalik Buterin, May 2024
That’s a co-founder buying extra hardware just to hold the chain. It’s why node size is treated as one of the real threats to keeping Ethereum decentralized, and why roadmap work like EIP-4444 (history expiry) aims to shrink a node’s footprint below 100 GB down the line. Until then, an archive node’s terabytes are simply the cost of remembering everything.
Does an archive node make you more decentralized?
Here’s a myth worth killing: keeping full history doesn’t make you a more important part of the network. Decentralization comes from many independent parties each validating the chain, and a lean node already does that in full. The extra history is a convenience for querying the past — it isn’t a bigger vote in consensus. If anything, the sheer weight of an archive pushes storage toward a handful of large operators, which cuts the other way. That’s the tension Buterin keeps flagging: the chain’s history has to live somewhere, but forcing every machine to keep all of it would price regular people out. The healthy shape is lots of light, lean nodes doing the validating, and a smaller set of heavy ones keeping the long record. None of that is a knock on the heavy option — it’s just a reminder that it’s a data tool, not a bigger stake in the network.
Which clients run archive mode — Geth, Erigon, Reth
Not every client stores an archive the same way, and the gap is enormous. Geth (Go Ethereum) is the most-used client and the reference implementation, but in classic archive mode it’s also the hungriest — historically 12 TB and up. Erigon was built to fix exactly that; its staged sync and flat storage pack the same archive into under 3 TB, which is why ethereum.org steers archive operators toward it. Reth, the newer Rust client from Paradigm, lands around 2.8 TB and has become a favorite for its speed. Nethermind and Besu round out the field with their own archive options. The takeaway is simple: if you’re set on running an archive node yourself, the client you pick can swing the storage bill by 4x or more — so choose before you buy drives.
Full node vs archive node: the key differences
So where does that leave the full node vs archive node decision? Line them up and the trade-offs are clear. Both validate the chain and both stay in sync with the network — that part’s identical. The split is history, and everything history drags with it: disk size, sync time, and the range of questions each node can answer.
| Attribute | Full node | Archive node |
|---|---|---|
| Current state | Yes | Yes |
| Historical state | Last ~128 blocks | Every block since genesis |
| Typical disk (2026) | ~1–1.5 TB | ~3 TB (Erigon) to 12+ TB (legacy Geth) |
| Initial sync | Hours to days | Up to ~1 month |
| Grows over time | Slowly | Relentlessly |
| Best for | Wallets, dapps, validating | Explorers, analytics, audits |
Read the table and a rule of thumb falls out. If your project only needs what happened recently, a full node is cheaper, faster to sync, and easier to maintain. If you need to reach deep into the past — reliably, and often — that’s archive territory, and there’s no shortcut around the storage. The mistake people make is defaulting to archive mode “just in case,” then paying for 10 TB they query twice a year.
Who actually needs an archive node?
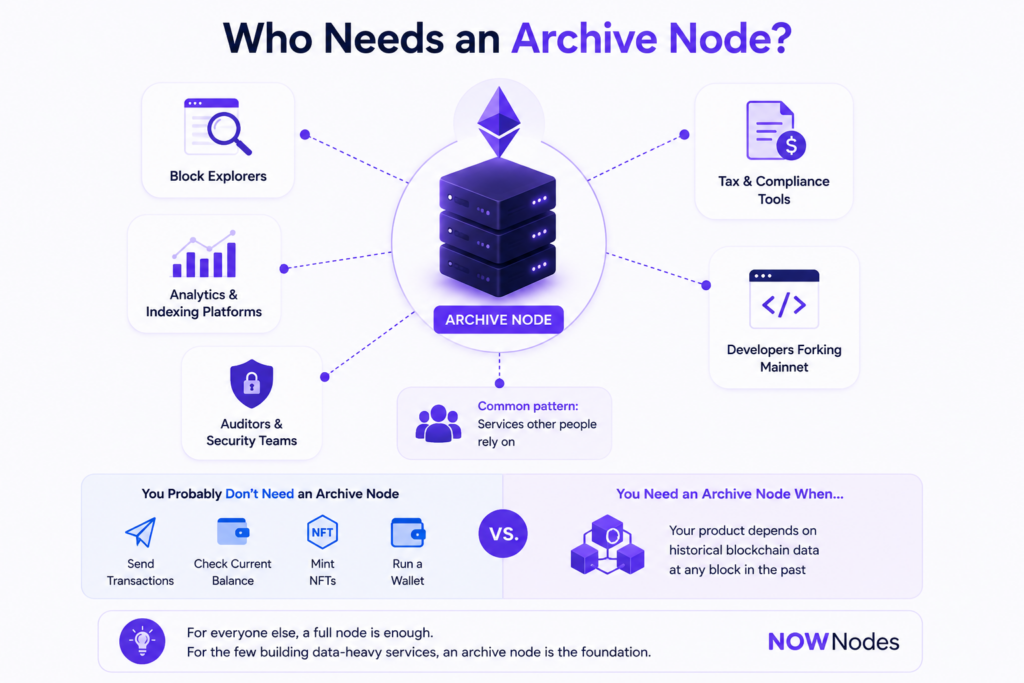
Most people never need one. Sending transactions, checking a current balance, minting an NFT, running a wallet — none of that touches historical state, so a full node handles it fine. Archive nodes earn their keep in a narrower set of jobs, where fast access to the deep past is the entire point. The common thread is that someone downstream is depending on historical data being there, on demand. If you’re building any of the following, one stops being optional.
- Block explorers — showing every historical transaction and balance for any address means reading the full history, constantly.
- Analytics and indexing platforms — dashboards, indexers, and on-chain research replay old state to build their numbers.
- Auditors and security teams — reconstructing exactly what a contract held at the moment of an exploit needs block-by-block history.
- Tax and compliance tools — cost-basis and reporting depend on balances at specific past dates.
- Developers forking mainnet — testing against real historical state with tools like Foundry or Hardhat pulls from an archive node.
Notice the pattern: these are services other people rely on, not day-to-day wallet use. That’s also why so few teams run their own — the audience that needs the data is small, but the data itself is enormous. For everyone else, a full node, or a shared endpoint that already has archive access, covers the job without the hardware bill.
How to run or reach a node without the wait
You’ve got two ways to get node data: run the node yourself, or connect to one someone else runs. Running your own gives you full control and full responsibility — the drives, the sync, the updates, the uptime. For a full node, that’s manageable on a decent machine. For an archive node, you’re signing up to babysit multiple terabytes that only grow, plus an initial sync that can eat a month before the node is even useful. And it doesn’t stop at that first sync — you’re on the hook for client updates, disk monitoring, and the occasional 3 a.m. restart when something wedges.
The other path skips all of that. A provider like NOWNodes already runs full and archive nodes for Ethereum and 100+ other chains, so you connect to a ready endpoint instead of building one. You get archive-depth history without the drives or the month-long sync, usually starting on a free tier before you scale up. If you outgrow shared infrastructure, you can move to a dedicated node later — but for most teams, reaching an archive node this way is the difference between shipping now and syncing until next month.
Conclusion
Strip it down and full node vs archive node is a question about memory. A full node remembers enough to keep the chain honest and serve the present — for about a terabyte and a quick sync. An archive node remembers all of it, back to 2015, and charges you in terabytes and time for the privilege. Neither one is “better.” The right call is whichever matches what you’re building: recent state, or the whole history.
And if you’d rather not lose a month to syncing, that’s the easy part to outsource. A hosted full or archive node from NOWNodes gets you the data today — full history, no drives, no weeks-long wait. You can start on a free tier and scale up only when your traffic does.
FAQ
What’s the real difference between a full node and an archive node?
History, mostly. A full node keeps the current state and roughly the last 128 blocks, then prunes the rest to save space. An archive node keeps every historical state since genesis, which makes it far larger but able to answer questions about the deep past instantly. Both validate the chain the same way — the difference is how much they remember.
Is an archive node just a bigger full node?
Essentially, yes — with a catch. An archive node does everything a full node does, then stores every past state on top. So it isn’t a different network role; it’s a full node configured to keep the history instead of pruning it. The “bigger” part is dramatic, though: think 3–12 TB versus around 1 TB.
How big is an Ethereum archive node in 2026?
It depends on the client. Erigon fits an archive in under 3 TB, Reth lands near 2.8 TB, and legacy Geth can still top 12 TB, while newer path-based storage brings Geth closer to ~2 TB. A full node, by comparison, runs around 1–1.5 TB total. Those figures climb every year as the chain grows, so treat them as a floor, not a ceiling.
What are the main node types on a blockchain?
Three: light, full, and archive. A light node stores only block headers and asks full nodes for the rest, which suits phones and small devices. A full node holds the current state and recent history. An archive node holds the entire history back to genesis. Most application work comes down to that last choice.
Do I need an archive node?
Probably not, unless you’re serving historical data to other people. Wallets, dapps, and everyday transactions live entirely in recent state, so a full node covers them. You need an archive node when your product reaches repeatedly into the deep past — explorers, analytics, audits, or tax tools. If that’s not you, a full node saves you a lot of disk and hassle.
Can I run an archive node on a laptop?
You can, but it’s a stretch. As Vitalik Buterin’s own setup shows, an archive-capable node can eat 2+ TB and force you to add a dedicated drive. It’ll also sync for weeks and keep growing after that. For anything you actually depend on, a server or a hosted node is the saner route.


